Predicting NBA Drafts with Machine Learning
November 2020 - December 2020

Overview
For our semester project in our Intro to Machine Learning class, we attempted to predict the
efficiency of draft prospects based upon their college stats. We were interested in this unique
problem because NBA teams spend millions of dollars every year signing, at times, immature
19-year-old kids with the hope that they could be the new franchise player, but all too often
players bust. And on the flip side, underestimated players can make a huge impact, just think of
pick
number 199 of 200 in the 2000 NFL Draft, his name is Tom Brady.
We believed that a machine could remove the typical bias that scouts give towards players and try to
find trends where players might not follow the mold. We began by scraping as much data as we could
from SportsReference.com about NBA and NCAA players dating back to 2010. Our decision to only look
as far back as 2010 was based on how the game has changed and remove generational bias. The college
stats we used as inputs to evaluate a player were minutes played, career points, field goal
percentage, three-point percentage, height, weight, and their player efficiency rating (PER). To
evaluate a player, we chose to average a player’s PER over their first five years in the league to
best represent how well a player will benefit the team that drafted them before typically changing
teams via trades or free agent signing. The player efficiency rating (PER) is a weighted rating used
to combines all a player’s stats into one category. We concluded that it was the best rating that
wouldn’t favor one position over another, nor give unfair advantage towards a bench player on a
championship team compared to the best player on a worse team. Due to the nature of the draft, the
best college players sign with the worst NBA teams, so great players might never win a championship
due to factors outside of their control.
We found that our models failed pretty miserably overall, and that most of the time a line could
better describe the data than our model. After trial and error we finally found that K-Nearest
Neighbor started to explain the data, but still not well. Our algorithm was just as susceptible to
picking draft busts as current teams are already, however there were a couple of silver linings. Our
algorithm seemed to do well at predicting successful players who were drafted later.
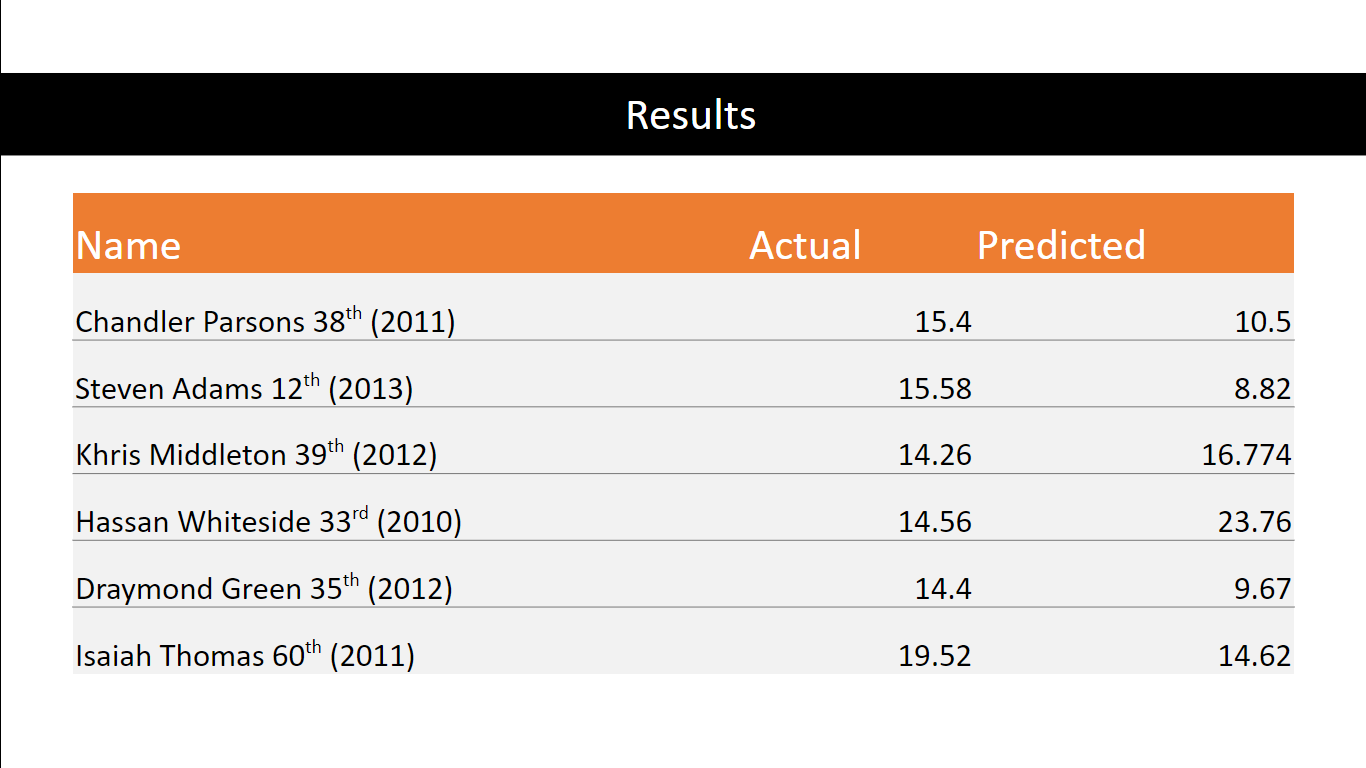 Predicted vs Actualy results from mid-tier picks. Sometimes our model got it right, and sometimes it
didn't. One might say 99% of the time it's 50% correct
Predicted vs Actualy results from mid-tier picks. Sometimes our model got it right, and sometimes it
didn't. One might say 99% of the time it's 50% correct
My Contributions
I proposed this project idea initially and two classmates, fellow basketball fans, decided to join. I wrote the web scraper code to gather all the stats needed across two different websites and combined the stats together to make a cohesive input into the machine learning algorithm. The other two teammates used my data across several different machine learning approaches and ensembles to find the highest accuracy.
Things I Learned and Skills Developed
I learned that machine learning models are hard and are not quick fixes like some of the lab assignments were in class. This was a typical trend across the class, most of our implementations didn’t work, and rightfully so! It should take more work than a couple of college kids writing a simple model in a few hours to shake up multi-billion-dollar industries like professional sports, animation, or even the stock market. But I did learn about ways to gather large data, evaluate models and how to pick models that can best describe our unique data while doing a practical application.


